6 Momente von Zufallsvariablen
Bisher haben wir die “Zufälligkeit’’ einer Zufallsvariable \(X\) über deren Verteilungsfunktion oder deren (Zähl-)Dichte charakterisiert. Einerseits hat sich dies als äußerst nützlich erwiesen, weil wir damit die Verteilung von \(X\) eindeutig und vollständig beschrieben haben. Andererseits lassen sich auf Basis der Dichte oder Verteilungsfunktion viele einfache Fragestellungen nicht ad-hoc beantworten.
Insbesondere die folgenden zwei zentralen Fragen über eine Zufallsvariable \(X\) blieben bisher unbeantwortet:
- Welchen Wert nimmt \(X\) “im Mittel’’ an?
- Wie sind die Werte von \(X\) um diesen “Mittelwert’’ gestreut?
Auf gewisse Weise haben wir uns diesen Fragen in Beispiel 4.5 über die \(k\)-\(\sigma\)-Regel für die Normalverteilung genähert. Nichtsdestotrotz erfüllt erstens nicht jede Verteilung diese Regel und zweitens beantwortet sie die Fragen nur vage. Wünschenswert wären Kennzahlen, anhand derer wir die Antwort auf die Fragen ablesen können. In diesem Kapitel geht es darum, solche Kennzahlen zu beleuchten.
Definition 6.1 (Erwartungswert)
Für eine diskrete Zufallsvariable \(X\) ergibt sich der Erwartungswert \(\mathbb{E}X\) von \(X\) als der mit der Zähldichte gewichtete Mittelwert aller Werte von \(X\), d.h. \[\begin{align} \mathbb{E}X = \sum_{x \in X(\Omega)} x \mathbb{P}(X = x), \tag{1} \label{eq: Erwartungswert diskret} \end{align}\] unter der Voraussetzung, dass \[\begin{align} \mathbb{E}\vert X \vert = \sum_{x \in X(\Omega)} \vert x \vert \mathbb{P}(X = x) < \infty. \tag{2} \label{eq: Integrierbarkeit diskret} \end{align}\]
Für eine absolutstetige Zufallsvariable \(X\) ergibt sich der Erwartungswert \(\mathbb{E}X\) von \(X\) als der mit der Dichtefunktion “gewichtete Mittelwert aller Werte’’ von \(X\), d.h. \[\begin{align} \mathbb{E}X = \int_\mathbb{R} x f_X(x)\ dx, \label{eq: Erwartungswert stetig} \tag{3} \end{align}\] unter der Voraussetzung, dass \[\begin{align} \mathbb{E} \vert X \vert = \int_\mathbb{R} \vert x \vert f_X(x)\ dx < \infty. \label{eq: Integrierbarkeit stetig} \tag{4} \end{align}\]
Annahme 6.1
Mit dem Erwartungswert kommen wir der ersten Frage zu Beginn dieses Kapitels deutlich näher. Aber er beantwortet die Frage nicht zu unseren vollständigen Zufriedenheit. Wir sagen umgangssprachlich, dass eine Zufallsvariable \(X\) “im Mittel’’ den Erwartungswert \(\mathbb{E}X\) annimmt. Allerdings wird uns Beispiel 6.1 zeigen, dass eine Zufallsvariable nicht notwendigerweise den Erwartungswert mit positiver Wahrscheinlichkeit annehmen kann.
Der Erwartungswert ist dennoch eine wichtige Kenngröße und fürs Erste geben wir uns mit dieser Näherung an Frage 1 zufrieden. Bzgl. der Interpretation des Erwartungswertes wird uns das sogenannte starke Gesetz der großen Zahlen in Kapitel 8 weitere Erkenntnisse liefern.Die Gleichung \(\eqref{eq: Erwartungswert stetig}\) ist letztendlich nichts anderes die infinitesimale Version der Gleichung \(\eqref{eq: Erwartungswert diskret}\), die sich aus der Notwendigkeit der “Summation von überabzählbar vielen Werten’’ ergibt.
Man spricht davon, dass \(X\) integrierbar ist, falls \(\eqref{eq: Integrierbarkeit diskret}\) bzw. \(\eqref{eq: Integrierbarkeit stetig}\) erfüllt ist.
Allgemein und ohne die Unterscheidung zwischen stetigen und diskreten Zufallsvariablen definiert man den Erwartungswert \(X: \Omega \rightarrow \mathbb{R}\) als Lebesgue-Integral bzgl. dem Wahrscheinlichkeitsmaß \(\mathbb{P}\), d.h. \[\begin{align} \mathbb{E}X = \int_\Omega X(\omega)\ \mathbb{P}(d\omega), \label{eq: Erwartungswert allgemein} \tag{5} \end{align}\] falls \[\begin{align*} \int_\Omega \max \{ X(\omega), 0 \}\ \mathbb{P}(d\omega) < \infty \text{ oder } \int_\Omega -\min \{ X(\omega), 0 \}\ \mathbb{P}(d\omega) < \infty. \end{align*}\] Man bemerke dabei, dass die Gleichung \(\eqref{eq: Erwartungswert allgemein}\) über einen Maßtransport bzgl. der Verteilung \(\mathbb{P}_X\) zu den Gleichungen \(\eqref{eq: Erwartungswert diskret}\) bzw. \(\eqref{eq: Erwartungswert stetig}\) führt.
Beispiel 6.1
Für die Augenzahl \(X\) eines üblichen Würfels gilt \[\begin{align*} \mathbb{E}X = \sum_{j = 1}^{6} j \mathbb{P}(X = j) = \frac{1}{6} \sum_{j = 1}^{6} j = 3{.}5. \end{align*}\]
Für \(X \sim \mathcal{N}(\mu, \sigma^2)\) lässt sich zeigen, dass \(\mathbb{E}X = \mu\). Anschaulich lässt sich dies für die Normalverteilung anhand von Abbildung 4.2 erkennen, da die Dichten bei \(\mu\) das einzige Maximum annimmt und symmetrisch, um \(\mu\) ist.
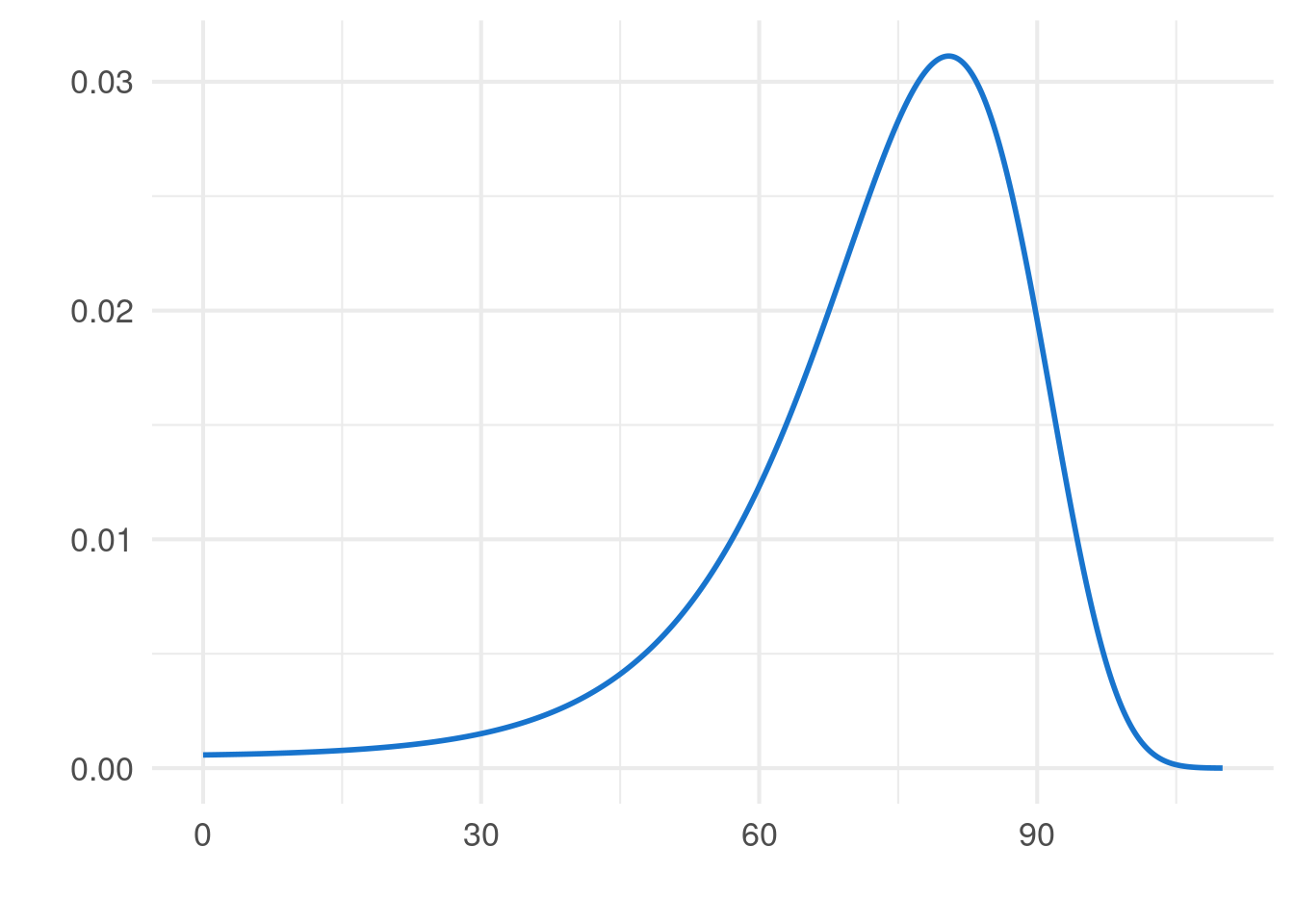
Wichtig: Der Erwartungswert ergibt sich nicht immer als das Maximum der Dichte. Hier wurde nur der Spezialfall der Normalverteilung besprochen.In Beispiel 4.6 haben wir festgestellt, dass die Exponentialverteilung keine sinnvolle Verteilung für die Lebensdauer \(T\) eines Menschen ist. schlägt als mögliche Alternative die sogenannte Gompertz-Makeham Verteilung vor. Dessen Dichtefunktion ist definiert als \[\begin{align*} f_T(x) = \Big( \alpha e^{\beta x} + \lambda \Big) \exp \bigg\{ -\lambda x - \frac{\alpha}{\beta} (e^{\beta x}-1) \bigg\} \mathbb{1}\{ x > 0 \}, \end{align*}\] wobei \(\alpha, \beta, \lambda > 0\) Parameter dieser Verteilung sind. Norberg (2020) empfiehlt, die Parameter so zu wählen, dass \[\begin{align*} \alpha = 7{.}5858 \cdot 10^{-5}, \quad \beta = \log(1{.}09144), \quad \lambda = 5\cdot 10^{-4} \end{align*}\] und bezeichnet diese spezielle Verteilung als G82M-Verteilung (siehe Abbildung 6.1). Der Erwartungswert von \(T\) ist nun gegeben als \[\begin{align*} \int_{0}^{\infty} x f_T(x)\ dx \approx 72{.}65, \end{align*}\] wobei wir die Berechnung mit numerischen Mitteln durchgeführt haben.
Häufig ist man nicht nur an dem Erwartungswert einer Zufallsvariable \(X\) interessiert. Oft interessiert man sich auch für den mittleren Wert der Zufallsvariable \(g(X)\), wobei \(g\) eine messbare Funktion ist, sodass \(g(X)\) integrierbar ist (sonst ist der Erwartungswert \(\mathbb{E}g(X)\) gar nicht erst definiert). Glücklicherweise liefert uns das folgende Theorem eine Möglichkeit, um die Berechnung von \(\mathbb{E}g(X)\) analog zur Berechnung von \(\mathbb{E}X\) durchzuführen.
Theorem 6.1 (“Law of the unconscious statistician’’ - LOTUS) Es sei \(X\) eine Zufallsvariable mit Dichtefunktion \(f_X\) bzw. Zähldichte \(\mathbb{P}(X = k)\) und \(g\) eine reellwertige Funktion, sodass \(g(X)\) integrierbar ist. Dann gilt \[\begin{align} \mathbb{E}g(X) = \begin{cases} \int_{\mathbb{R}} g(x) f_X(x)\ dx, &\text{ falls $X$ stetig}\\ \sum\limits_{x \in X(\Omega)} g(x) \mathbb{P}(X = x), &\text{ falls $X$ diskret} \end{cases} \label{eq: LOTUS} \tag{6} \end{align}\]
Annahme 6.2
Wir benötigen für die Berechnung von \(\mathbb{E}g(X)\) die Dichtefunktion bzw- Zähldichte der Zufallsvariable \(g(X)\) nicht. Intuitiv lässt sich dies darüber erklären, dass wir durch die Funktion \(g\) die (reellen) Werte, die wir einem Ereignis zuordnen, verändern, jedoch die Wahrscheinlichkeit der entsprechenden Ereignisse unverändert lassen. Dementsprechend müssen wir für den neuen Erwartungswert lediglich die neuen Werte mit den alten Wahrscheinlichkeiten gewichten.
Trotz der intuitiven Erklärung von Theorem 6.1 ist dies keine Definition, weswegen die Gleichung \(\eqref{eq: LOTUS}\) formal bewiesen werden muss. Da es Studenten manchmal unterstellt wird, diesen Unterschied nicht zu erkennen, wird dieses Theorem auch manchmal “Law of the unconscious statistician’’ genannt.1
Aus der Linearität des Integrals bzw. der Summe ergibt sich aus Theorem 6.1 die Linearität des Erwartungswertes, d.h. für alle \(a, b \in \mathbb{R}\) gilt \(\mathbb{E}[aX+b] = a\mathbb{E}X + b\).
Falls \(g(x) = x^{p}\) mit \(p \in \mathbb{N}\), so nennt man \(\mathbb{E}[X^p]\) das \(p\)-te Moment von \(X\).
In Theorem 6.1 wurde vorausgesetzt, dass \(g(X)\) integrierbar ist. Allgemein bezeichnet man die Klasse der integrierbaren Zufallsvariablen mit \[\begin{align*} \mathcal{L}^1 := \Big\{ X: \Omega \rightarrow \mathbb{R} \Big\vert X \text{ messbar und } \mathbb{E}\vert X \vert < \infty \Big\}. \end{align*}\] In diesem Fall könnten wir also \(g(X) \in \mathcal{L}^1\) schreiben. Analog dazu definiert man die Klasse der Zufallsvariablen mit \(p\)-tem Moment als \[\begin{align*} \mathcal{L}^p := \Big\{ X: \Omega \rightarrow \mathbb{R} \Big\vert X \text{ messbar und } \mathbb{E}[\vert X \vert^p] < \infty \Big\}. \end{align*}\]
Der Erwartungswert hilft uns, den “Mittelwert’’ einer Zufallsvariable zu bestimmen. Damit konnten wir die erste Frage zu Beginn des Kapitels
- Welchen Wert nimmt \(X\) “im Mittel’’ an?
hinreichend gut zu beantworten. Und wir können das gleiche Konzept auch auf die zweite Frage
- Wie sind die Werte von \(X\) um diesen “Mittelwert’’ gestreut?
anwenden. Dazu betrachten wir (zufällige) Abweichungen der Form \(Z = f(X - \mathbb{E}X)\) und ermitteln die “erwartete’’ Abweichung als Erwartungswert \(\mathbb{E}Z\) von \(Z\). Hierbei sind häufige Wahlen von \(f\) gegeben durch \(f(x) = \vert x \vert\) (absolute Abweichung) oder \(f(x) = x^2\) (quadratische Abweichung). Insbesondere letztere Form wird so häufig verwendet, dass sie einen eigenen Namen erhält.
Definition 6.2 (Varianz, Standardabweichung) Für eine Zufallsvariable \(X \in \mathcal{L}^2\) bezeichnen wir die mittlere quadratische Abweichung \[\begin{align*} \text{Var}(X) := \mathbb{E}[(X-\mathbb{E}X)^2] \end{align*}\] als Varianz von \(X\). Außerdem bezeichnen wir die Größe \(\sqrt{\text{Var}(X)}\) als Standardabweichung von \(X\).
Annahme 6.3
Die Varianz wird gerne verwendet, da sie große Abweichungen stärker “bestraft’’ als es die mittlere absolute Abweichung \(\mathbb{E}\vert X - \mathbb{E}X \vert\) tun würde. Dies ist oftmals eine gewünschte Eigenschaft. Allerdings hat die Varianz nicht mehr die gleiche Einheit, wie die zu untersuchende Größe (bspw. \(\text{EUR}^2\) statt \(\text{EUR}\), falls \(X\) eine Zufallsvariable aus dem Finanzbereich ist). Deswegen nutzt man für einheitsbezogene Aussagen die Standardabweichung.
Anhand der Definition erkennt man schnell, dass für alle \(a, b \in \mathbb{R}\) gilt \(\text{Var}(aX+b) = a^2 \text{Var}(X)\). Anschaulich ist dies auch ohne die Formel erklärbar:
Da man mit der Varianz die Streuung einer Zufallsvariable untersucht, ist schnell klar, dass die Verschiebung aller Werte um \(b \in \mathbb{R}\) die Streuung unverändert lässt. Die Werte sind lediglich, um einen neuen Mittelwert gestreut.
Die Streckung der Streuung um einen Faktor \(a \in \mathbb{R}\) bewirkt, dass die quadratische Streuung sich um den Faktor \(a^2\) verändert.
Die Varianz lässt sich oft am einfachsten über die Verschiebungsformel \[\begin{align*} \text{Var}(X) = \mathbb{E}[X^2]- \mathbb{E}[X]^2 \end{align*}\] berechnen.
Oftmals bezeichnet man die Varianz auch als zweites zentriertes Moment. Allgemein definiert man das \(p\)-te zentrierte Moment einer Zufallsvariable \(X \in \mathcal{L}^{p}\) als \(\mathbb{E}[(X-\mathbb{E}X)^{^p}]\).
Beispiel 6.2 Für eine Zufallsvariable \(X \sim \mathcal{N}(\mu, \sigma^2)\) lässt sich zeigen, dass \(\text{Var}(X) = \sigma^2\). Anschaulich erkennt man dies für die Normalverteilung auch an dessen Dichte Abbildung 4.2, da sich die “Breite’’ der Glockenkurve mit dem Parameter \(\sigma\) verändert.