7 Zusammenhang von Zufallsvariablen
Bisher haben wir nur den Erwartungswert von eindimensionalen Zufallsvariablen untersucht. Wie wir in Kapitel 5 bereits besprochen haben, reicht es jedoch oft nicht aus, nur einzelne Zufallsvariablen zu betrachten. Daher bietet es sich an, die Konzepte von Kapitel 6 für Zufallsvektoren zu übertragen. Dies eröffnet uns auch die Möglichkeit, Zusammenhänge abseits der bisherigen binären Unterscheidung von abhängig und unabhängig zu beleuchten.
Zunächst stellen wir fest, dass der “Erwartungswert’’ eines Zufallvektors \(X = (X_1, \ldots, X_n)\) mit \(n \in \mathbb{N}\) lediglich ein Vektor der Erwartungswerte der Komponenten \(X_i\), \(i = 1, \ldots, n\), ist. Wir schreiben \[\begin{align} \mathbb{E}X = \big( \mathbb{E}X_1, \ldots, \mathbb{E}X_n \big) \label{eq: Erwartungswertvektor} \tag{1} \end{align}\] und nennen \(\mathbb{E}X\) in diesem Fall den Erwartungswertvektor von \(X\).
Solange \(g\) eine reellwertige Funktion ist, können wir - genau wie in Theorem 6.1 -den Erwartungswert einer (eindimensionalen) Zufallsvariable \(g(X)\) bestimmen, auch wenn \(X = (X_1, \ldots, X_n)\) ein Zufallsvektor ist. Dazu überlegt man sich analog zu Annahme 6.2, dass man lediglich alle Werte \(g(x_1, \ldots, x_n)\), \(x_i \in X_i(\Omega)\), \(i = 1, \ldots, n\), mit der ursprünglichen (Zähl-)-Dichte von \(X\) gewichten muss. In diesem Fall nimmt man dafür die gemeinsame (Zähl-)Dichte und berücksichtigt alle Werte über ein \(n\)-fach Integral bzw. über eine \(n\)-fache Summe.
Theorem 7.1 (LOTUS - Mehrdimensional) Es sei \(X = (X_1, \ldots, X_n)\) ein \(n\)-dimensionaler Zufallsvektor und \(g: \mathbb{R}^n \rightarrow \mathbb{R}\) eine reellwertige Funktion, sodass \(g(X) \in \mathcal{L}^1\). Dann gilt \[\begin{align} \mathbb{E}g(X) = \begin{cases} \int_{\mathbb{R}} \dots \int_{\mathbb{R}} g(x_1, \ldots, x_n) f_{(X_1, \ldots, X_n)}(x_1, \ldots, x_n)\ dx_n \dots dx_1, &\text{ $X$ stetig}\\ \sum\limits_{x_1 \in X_1(\Omega)} \dots \sum\limits_{x_n \in X_n(\Omega)} g(x_1, \ldots, x_n) \mathbb{P}(X_1 = x_1, \ldots, X_n = x_n), &\text{ $X$ diskret} \end{cases} \label{eq: LOTUS mehrdim} \tag{2} \end{align}\]
Die Gleichung \(\eqref{eq: Erwartungswertvektor}\) ist eine einfache Verallgemeinerung des Erwartungswertes für Zufallsvektoren. Im Kontrast dazu ist die Verallgemeinerung der Varianz eines Zufallsvektors \(X\) nicht komponentenweise zu verstehen. Dies liegt daran, dass man unter der Quadrierung eines Vektors \(x\) üblicherweise nicht eine komponentenweise Quadrierung versteht. Stattdessen meint man in der Regel das Produkt \(xx^{t}\), wobei \(x^t\) die Transponierte von \(x\) ist.
Definition 7.1 (Kovarianz, Kovarianzmatrix) Es sei \(X\) ein \(n\)-dimensionaler Zufallsvektor mit \(X_i X_j \in \mathcal{L}^1\) für alle \(i, j = 1 \ldots, n\).
Dann bezeichnen wir \[\begin{align*} \text{Cov}(X_i, X_j) := \mathbb{E}[(X_i - \mathbb{E}X_i) (X_j - \mathbb{E}X_j)] \end{align*}\] als Kovarianz zwischen \(X_i\) und \(X_j\). Außerdem bezeichnen wir \[\begin{align*} \text{Cov}(X) :&= \mathbb{E}[(X- \mathbb{E}X) (X- \mathbb{E}X)^t] = \mathbb{E}\bigg[ \Big( (X_i - \mathbb{E}X_i) (X_j - \mathbb{E}X_j) \Big)_{i, j = 1, \ldots, n} \bigg] \\[2mm] &= \Big( \mathbb{E}[(X_i - \mathbb{E}X_i) (X_j - \mathbb{E}X_j)] \Big)_{i, j = 1, \ldots, n} \\[2mm] &= \big( \text{Cov}(X_i, X_j) \big)_{i, j = 1, \ldots, n} \end{align*}\] als Kovarianzmatrix des Zufallvektors \(X\).
Annahme 7.1
Offensichtlich gilt \(\text{Var}(X_i) = \text{Cov}(X_i, X_i)\) für alle \(i = 1, \ldots, n\). Deswegen wird \(\text{Cov}(X)\) auch Varianz-Kovarianzmatrix genannt. Außerdem ist \(\text{Cov}(X_i, X_j) = \text{Cov}(X_j, X_i)\), d.h. die Kovarianz ist symmetrisch bzgl. den Argumenten.
Eine mögliche Motivation, warum es sinnvoll ist, die Varianz auf diese Weise (und nicht komponentenweise) zu verallgemeinern, wird über die Berechnung der Varianz von Linearkombinationen von \(X_i\), \(i = 1, \ldots, n\), deutlich. Nehme dazu an, dass \(a = (a_1, \ldots, a_n) \in \mathbb{R}^n\). Dann lässt sich zeigen, dass \[\begin{align} \text{Var}(a X^t) = a \text{Cov}(X) a^t = \sum_{i = 1}^{n} \sum_{j = 1}^{n} a_i a_j \text{Cov}(X_i, X_j). \label{eq: Varianz Linearkombination} \tag{3} \end{align}\] Insbesondere gilt wegen Gleichung \(\eqref{eq: Varianz Linearkombination}\) und der Symmetrie der Kovarianz, dass \[\begin{align} \text{Var}(X_1 + X_2) = \text{Var}(X_1) + \text{Var}(X_2) + 2\text{Cov}(X_1, X_2). \label{eq: Varianz X+Y} \tag{4} \end{align}\]
Man nennt \(\mathbb{E}[X_iX_j]\) und \(\mathbb{E}[(X_i - \mathbb{E}X_i) (X_j - \mathbb{E}X_j)]\) das gemischte Moment und gemischte zentrierte Moment von \(X_i\) und \(X_j\).
Abgesehen davon, dass die Kovarianzmatrix eine Verallgemeinerung der Varianz ist, sind die darin enthaltenen Kovarianzen ein fundamentales Abhängigkeitsmaß zwischen den Zufallsvariablen. Normiert man die Kovarianz mit dem Produkt der entsprechenden Standardabweichungen, so erhält man den Korrelationskoeffizienten.
Definition 7.2 (Korrelationskoeffizient) Es seien \(X, Y \in \mathcal{L}^2\) zwei Zufallsvariablen. Dann bezeichnen wir \[\begin{align*} \rho(X, Y) := \frac{\text{Cov}(X, Y)}{\sqrt{\text{Var}(X)}\sqrt{\text{Var}(Y)}} \end{align*}\] als Korrelationskoeffizienten.
Annahme 7.2
Wie bei den meisten Normierungen, bewirkt hier die Normierung, dass die Kovarianz in einen besser interpretierbaren Wertebereich transformiert wird. Es gilt \(\rho(X, Y) \in [-1, 1]\) und man spricht davon, dass \(X\) und \(Y\) perfekt (negativ) korreliert sind, falls \(\rho(X, Y) = 1\) (bzw. \(\rho(X, Y) = -1\)).
Sind \(X\) und \(Y\) perfekt korreliert, so sind \(X\) und \(Y\) fast sicher linear abhängig, d.h. es gibt Koeffizienten \(a \neq 0\) und \(b \in \mathbb{R}\), sodass \(\mathbb{P}(Y = aX+b) = 1\). Aus diesem Grund spricht man auch davon, dass die Kovarianz den linearen Zusammenhang von \(X\) und \(Y\) quantifiziert.
Falls \(X\) und \(Y\) unabhängig sind, so gibt es keinen linearen Zusammenhang zwischen den beiden Größen und \(\rho(X, Y) = \text{Cov}(X, Y) = 0\). In diesem Fall gilt wegen Gleichung \(\eqref{eq: Varianz X+Y}\) auch \[\begin{align*} \text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y). \end{align*}\]
Aus \(\rho(X, Y) = 0\) lässt sich im Allgemeinen keine Unabhängigkeit folgern. Letztendlich liegt das daran, dass zwar kein linearer Zusammenhang zwischen \(X\) und \(Y\) vorliegt, aber bspw. immer noch ein quadratischer Zusammenhang bestehen kann (siehe Beispiel 7.1).
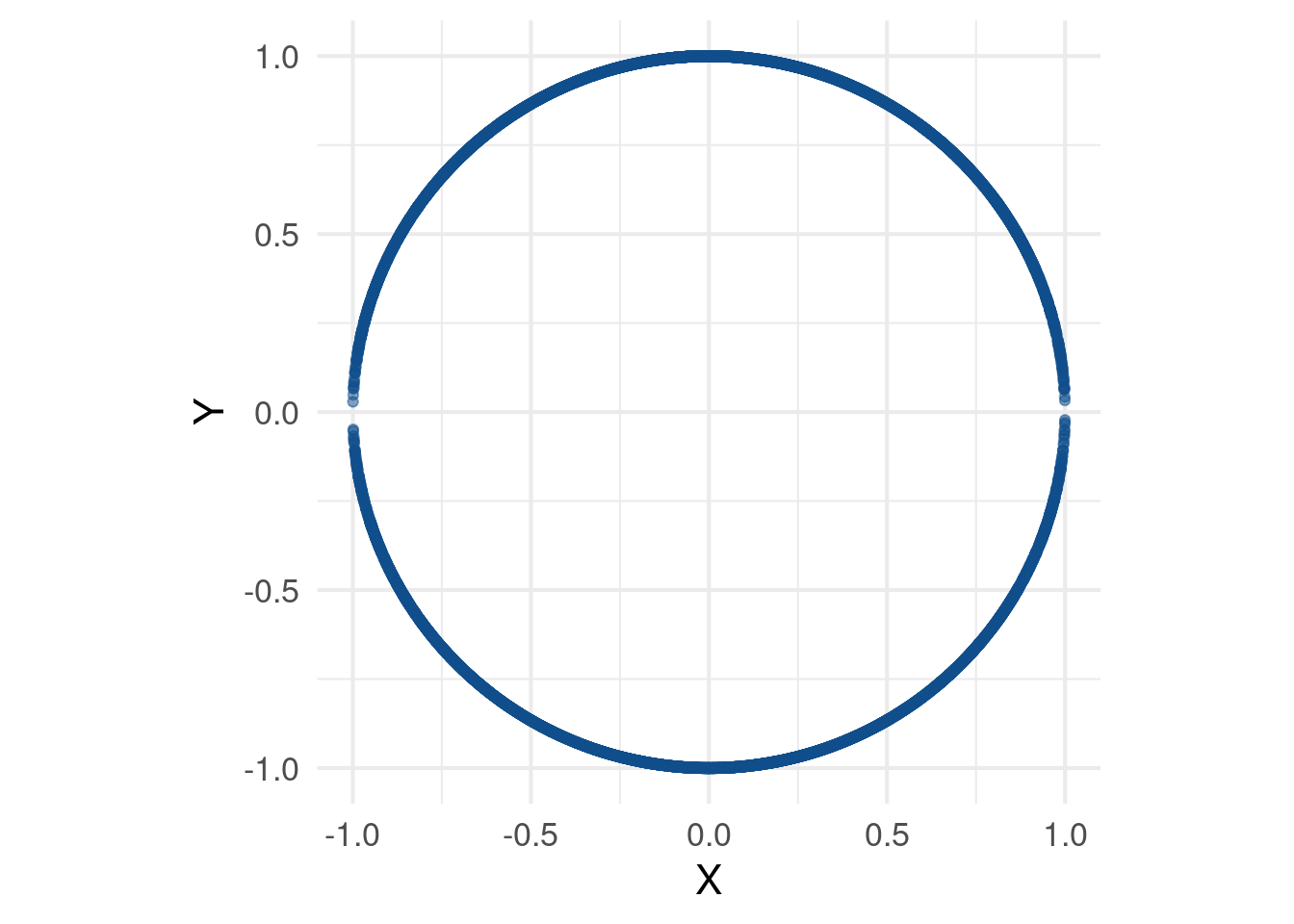
Beispiel 7.1 Es seien \(X \sim U(-1, 1)\) und \(Z \sim U(0, 1)\) unabhängig. Definiere nun \[\begin{align*} Y = \sqrt{1 - X^2} \mathbb{1}\{ Z < 0{.}5 \} - \sqrt{1 - X^2} \mathbb{1}\{ Z \geq 0{.}5 \}. \end{align*}\] Über das Gesetz der totalen Wahrscheinlichkeit lässt sich leicht feststellen, dass \(\text{Cov}(X, Y) = 0\). Allerdings sind \(X\) und \(Y\) nicht unabhängig, da \((X, Y)\) fast sicher auf der Kreislinie \(\{ (x, y) \vert x^2 + y^2 = 1 \}\) mit Radius 1 liegt (siehe Abbildung 7.1).
Annahme 7.3 (Korrelation und Kausalität) Keine Stochastik- bzw. Statistikeinführung kann ohne die Aussage “Korrelation ist nicht Kausalität’’ auskommen. Grundgedanke hinter der Aussage ist die Tatsache, dass ein Nachweis von Korrelation zwischen zwei Größen \(X\) und \(Y\) im Allgemeinen wenig Aussagekraft über einen kausalen Zusammenhang zwischen \(X\) und \(Y\) hat.
Insbesondere ist durch eine Korrelation nicht klar, ob \(X\) aus \(Y\) folgt oder andersherum. Außerdem könnten \(X\) und \(Y\) von einer dritten unbeobachteten Variable \(Z\) abhängen, die sowohl \(X\) als auch \(Y\) auslöst. Im Hinblick darauf, ist ein vielzitiertes Beispiel, die Beobachtung, dass Eisverkäufe (\(X\)) und Mordraten (\(Y\)) positiv korreliert sind.
In diesem Fall ist es wohl eher nicht sinnvoll zu argumentieren, dass Eisgenuss plötzliche Mordlust weckt (\(X \Rightarrow Y\)) oder dass sich Mörder gerne nach vollbrachter Tat ein Eis gönnen (\(Y \Rightarrow X\)). Plausibler ist allerdings die Überlegung, dass im Sommer (\(Z\)) sowohl mehr Eis gegessen wird als auch mehr gemordet wird (\(X \Leftarrow Z \Rightarrow Y\)) und die Korrelation von \(X\) und \(Y\) durch \(Z\) verursacht wird.
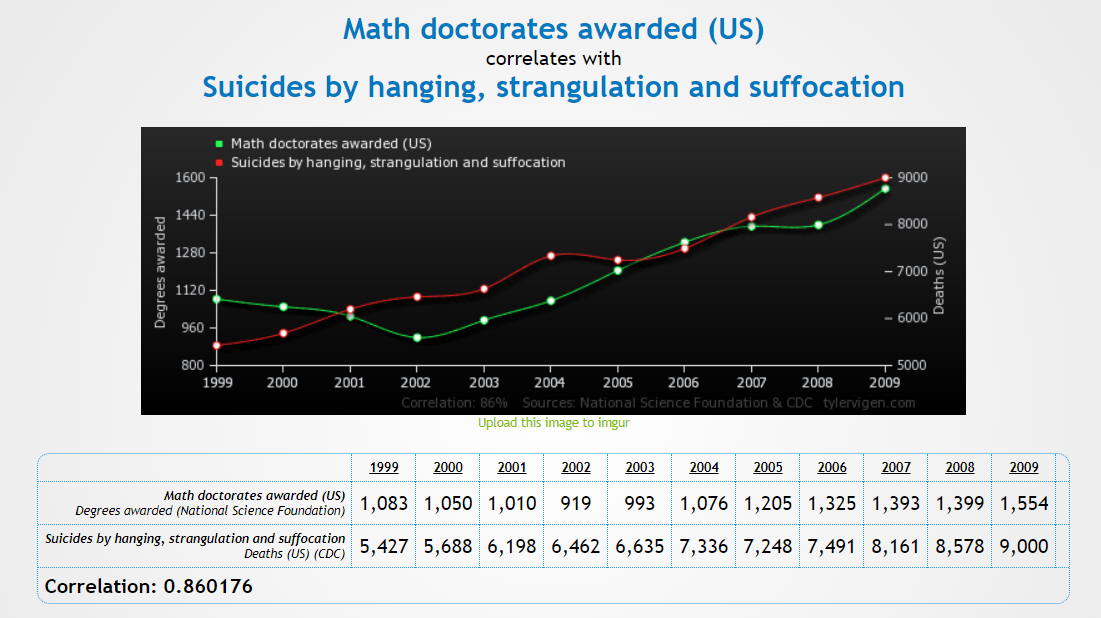
Weiterhin gibt es die Möglichkeit, dass eine Korrelation rein zufällig ist. Wenn man lang genug sucht, so findet man häufig irgendeine Korrelation, die nichts mit Kausalität zu tun hat. Eine Fundgrube an zufälligen Korrelationen findet sich auf tylervigen.com. Mein persönlicher Favorit findet sich in Abbildung 7.2 und beschreibt die Korrelation zwischen der Anzahl der in den USA verliehenen Doktortiteln im Bereich Mathematik und der Anzahl an Selbstmorden.
Klinische Studien versuchen diese Problematik “zu kontrollieren” und gelten in dieser Hinsicht als “Goldstandard”, da dort - vereinfacht gesagt - versucht wird, Studienteilnehmer in zwei möglichst ähnliche Menschengruppen zu unterteilen, wovon eine Gruppe das zu untersuchende Medikament und die andere Gruppe ein Placebo (Kontrollgruppe) erhält. Üblicherweise wissen weder die behandelnden Ärzte noch die Teilnehmer, wer in welcher Gruppe ist. Ein “signifikant besserer” Krankheitsverlauf innerhalb der Nicht-Placebogruppe wird dann der Wirkung des Medikaments zugeschrieben.
Der Zusammenhang zwischen Korrelation und Kausalität ist immer wieder ein kontroverses Thema. Neuerdings wird versucht, die Aussage “Korrelation ist nicht Kausalität’’ über sogenannte kausale Modelle zur Aussage”Manche Korrelationen sind Kausalität” zu entschärfen. In seinem populärwissenschaftlichen Buch (Pearl 2019) versucht der Informatiker und Philosoph Judea Pearl diese Sichtweise einem allgemeinen Publikum zu vermitteln und bietet dabei auch interessante Einblicke in die Historie der Statistik.